2009-11-13
■ [smalltalk] GNU Smalltalkのクラス階層をグラフ化した
世間の流行りを無視してSmalltalkネタ。
今日はGNU Smalltalkの組み込みクラスの 継承関係をGraphvizでプロットしてみました。(拡大: 560KB)
{kind=link}
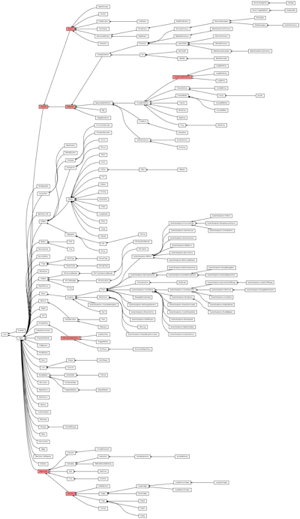
ソースは http://gist.github.com/233727
感想
- Rubyと比べると、モジュールがないのでシンプル。
- しかし多重継承もないのか。だからArrayやStringはComparable(もとい、Magnitude)じゃないんだ。
- 小クラス主義(と思って良いですか?)なので階層が深い。
- 例えば Array > ArrayedCollection > SequencableCollection > Collection > iterable > Object とかなってて凄い
- 仮想クラスは色を変えてみました
- が、判定方法が /I am an abstract class./ ってそれでいいのか
- クラスの説明に「僕は仮想クラスだよ」とか一人称で書いてるSmalltalk可愛い。
- ちょ、Continuationあるのかw
Graphvizについて
Graphvizについてのメモを書きました。複雑な構造をささっと可視化するととてもハッカーっぽい(イメージ)ので覚えておくと良いと思います。
どうでもいいおまけ
Smalltalkではメソッド呼び出し(Rubyの「.」)がスペースなので、自然言語DSLには強そう。
追記
リファレンスを眺めていたら、ノードにURLを付記する機能があることに気づいた。「ps2形式」で出力して、ghostscriptのps2pdfでPDFに変換すると、 ノードがクリックできるようになる。これは便利かも。
■ [ruby][scraping] load_or_get
スクレイパを書くとき、HTMLファイルを開発用に保存したりするのがめんどいのでなんとかならないか考えてみた。
WebからHTMLを取得するときに、キャッシュを作る。ファイル名はURLを%エンコードしたものを使う。
def load_or_get(url)
path = File.join("html", CGI.escape(url))
if File.exist?(path)
Nokogiri(File.read(path))
else
page = $agent.get(url)
File.open(path, "wb"){|f| f.write page.root.to_html}
page.root
end
end
doc = load_or_get("http://www.gnu.org/software/smalltalk/manual-base/html_node/Base-classes.html")
...
- 最初の起動時は、キャッシュがないので、WebからHTMLを取得して返す。
- このとき、%エンコードしたファイル名 (html/http%3A%2F%2Fwww.gnu.org%2F...みたいな) でHTMLを保存する。
- 2回目以降はファイルから読み込むので高速 (だしサーバに迷惑をかけない)。
本体(HTMLを操作するコード)の方では、ファイルから読み込んだかWebから取得したかを気にせずに書ける。load || get という感じ
WWW::Mechanizeの機能として標準装備されると嬉しいんだが。
使用例(上のエントリのやつです): http://gist.github.com/233727
個人的には http://gist.github.com/72574 と http://gist.github.com/232393 使ってます。Hpricot や Mechanize で目的の要素を取り出す試行錯誤は irb で行います。
間違いました。72574 じゃなくて http://gist.github.com/76140 こっちでした。
あ、こういうやつね。<br>ソース出さないとありがたくないかもね。実際問題、クラスのヒエラルキってブラウザで追えるでしょ?プレゼンにはいいでしょうけど。
SmalltalkならSmalltalkの中で完結して欲しかったね。